Deep Multi-Kernel Convolutional LSTM Networks and an Attention-Based Mechanism for Videos
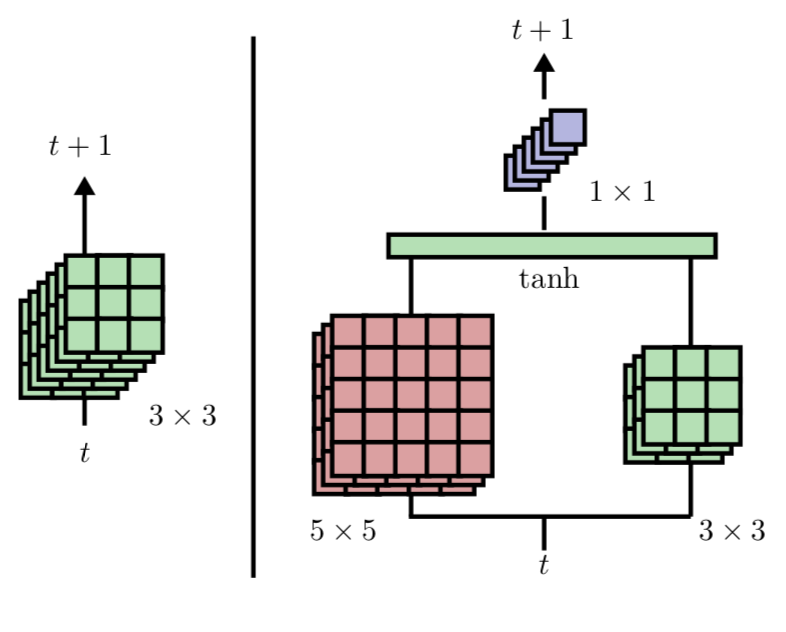
Action recognition greatly benefits motion under- standing in video analysis. Recurrent networks such as long short-term memory (LSTM) networks are a popular choice for motion-aware sequence learning tasks. Recently, a convolutional extension of LSTM was proposed, in which input-to-hidden and hidden-to-hidden transitions are modeled through convolution with a single kernel. This implies an unavoidable trade-off between effectiveness and efficiency. Herein, we propose a new enhancement to convolutional LSTM networks that supports accommodation of multiple convolutional kernels and layers. This resembles a Network-in-LSTM approach, which improves upon the aforementioned concern. In addition, we propose an attention-based mechanism that is specifically designed for our multi-kernel extension. We evaluated our proposed extensions in a supervised classification setting on the UCF-101 and Sports- 1M datasets, with the findings showing that our enhancements improve accuracy. We also undertook qualitative analysis to reveal the characteristics of our system and the convolutional LSTM baseline.