WiFi action recognition via vision-based methods
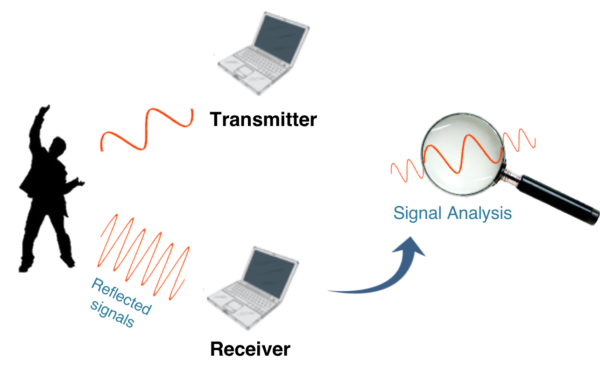
Action recognition via WiFi has caught intense attention recently because of its ubiquity, low cost, and privacy-preserving. Observing Channel State Information (CSI, a fine-grained information computed from the received WiFi signal) resemblance to texture, we transform the received CSI into images, extract features with vision-based methods and train SVM classifiers for action recognition. Our experiments show that regarding CSI as images achieves an accuracy above 85%. Our contributions include:, · To our best knowledge, we are the first to investigate the feasibility of processing CSI by vision-based methods with extendable learning-based framework. · We regard CSI of each Tx-Rx pair as a channel and investigate early and late fusion of multi-channels. · We could know where and what action user performs with location-awareness classification.