Unsupervised Semantic Feature Discovery for Image Object Retrieval and Tag Refinement
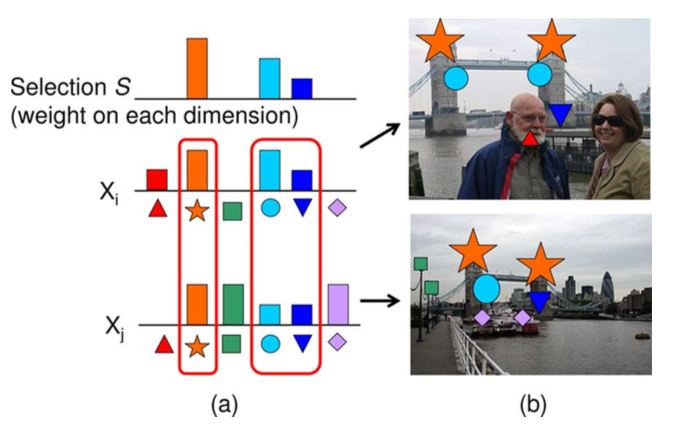
We have witnessed the exponential growth of images and videos with the prevalence of capture devices and the ease of social services such as Flickr and Facebook. Meanwhile, enormous media collections are along with rich contextual cues such as tags, geo-locations, descriptions, and time. To obtain desired images, users usually issue a query to a search engine using either an image or keywords. Therefore, the existing solutions for image retrieval rely on either the image contents (e.g., low-level features) or the surrounding texts (e.g., descriptions, tags) only. Those solutions usually suffer from low recall rates because small changes in lighting conditions, viewpoints, occlusions, or (missing) noisy tags can degrade the performance significantly. In this work, we tackle the problem by leveraging both the image contents and associated textual information in the social media to approximate the semantic representations for the two modalities. We propose a general framework to augment each image with relevant semantic (visual and textual) features by using graphs among images. The framework automatically discovers relevant semantic features by propagation and selection in textual and visual image graphs in an unsupervised manner. We investigate the effectiveness of the framework when using different optimization methods for maximizing efficiency. The proposed framework can be directly applied to various applications, such as keyword-based image search, image object retrieval, and tag refinement. Experimental results confirm that the proposed framework effectively improves the performance of these emerging image retrieval applications.