Summarizing While Recording: Context-Based Highlight Detection for Egocentric Videos
Abstract:
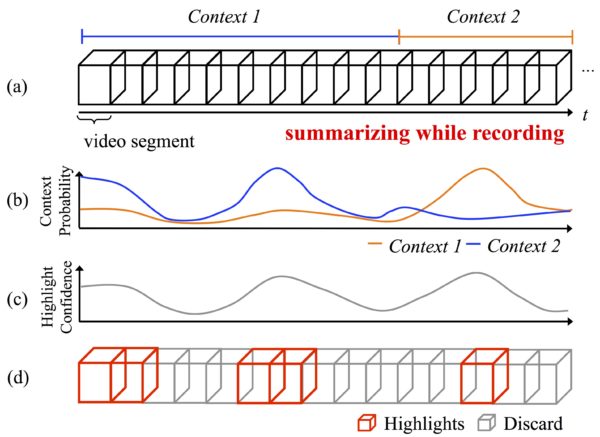
In conventional video summarization problems, contexts (e.g., scenes, activities) are often fixed or in a specific structure (e.g., movie, sport, surveillance videos). However, egocentric videos often include a variety of scene contexts as users can bring the cameras anywhere, which makes these conventional methods not directly applicable, especially because there is limited memory storage and computing power on the wearable devices. To resolve these difficulties, we propose a context-based highlight detection method that immediately generates summaries without watching the whole video sequences. In particular, our method automatically predicts the contexts of each video segment and uses a context-specific highlight model to generate the summaries. To further reduce computational and storage cost, we develop a joint approach that simultaneously optimizes the context and highlight models in an unified learning framework. We evaluate our method on a public Youtube dataset, demonstrating our method outperforms state-of-the-art approaches. In addition, we show the utility of our joint approach and early prediction for achieving competitive highlight detection results while requiring less computational and storage cost.