SEQDNet: Improving Missing Value By Sequential Depth Network
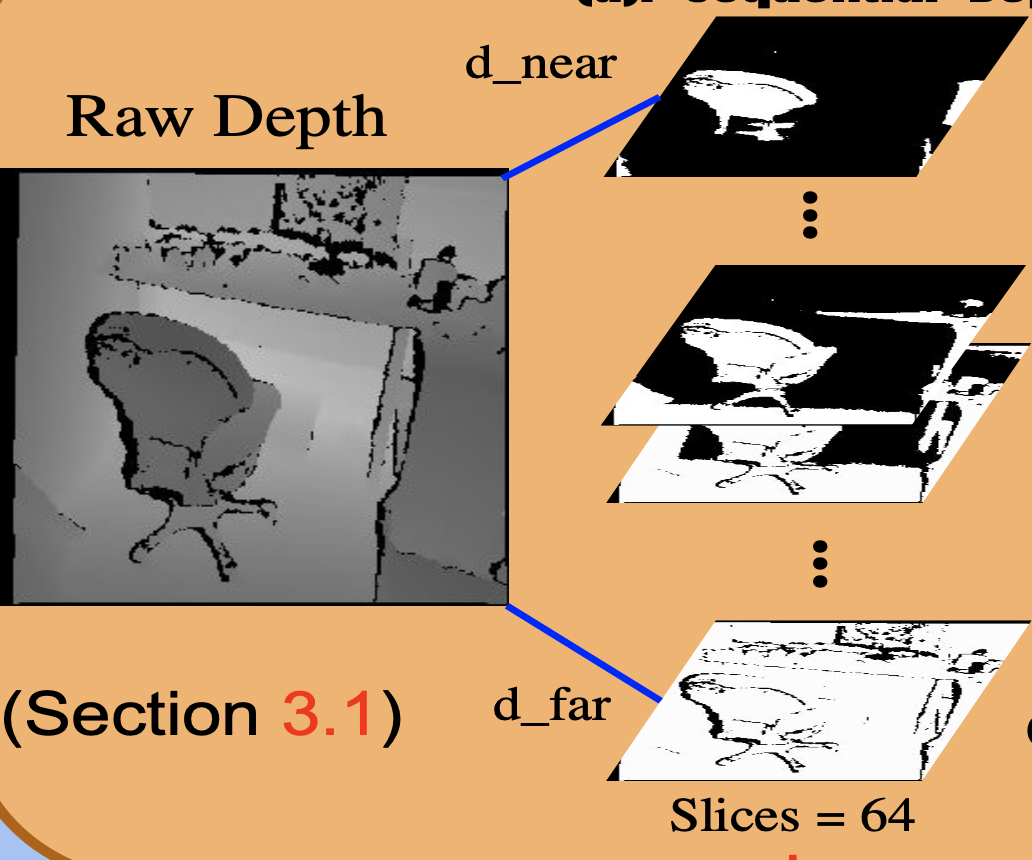
Depth estimation is essential for many applications, such as 3D reconstruction and object recognition. In practice, the captured depth images naturally suffer from the noise and invalid depth value, i.e, depth noise and depth hole. Despite making a process on filling a small number (less than 10%) of depth holes, the performance of the prior depth reconstruction systems drops significantly when coping with the larger hole region (up to 25%). To tackle this, we propose a novel Sequential Depth Networks (SeqDNet). Instead of filling holes in coarse scale, our model tends to leverage the information in the spatial structures constructed from depth images. There are two novel components in the proposed SeqDNet: (1) We slice the depth map from near to far, generating the spatial structure, named sequential depth. It provides residual depth information, which was neglected in previous works. (2) The edge awareness loss (EA Loss) matches the gradient of the depth map by controlling the weight with the normal map so as to provide additional instruction (whether the position is the edge or not) when filling depth holes. Experimental results show a significant performance gain on filling images with 25% depth holes using SeqDNet. Moreover, a comprehensive analysis is given to pave a path for future researches addressing the large hole size on the depth maps.