Scalable Face Track Retrieval in Video Archives using Bag-of-Faces Sparse Representation
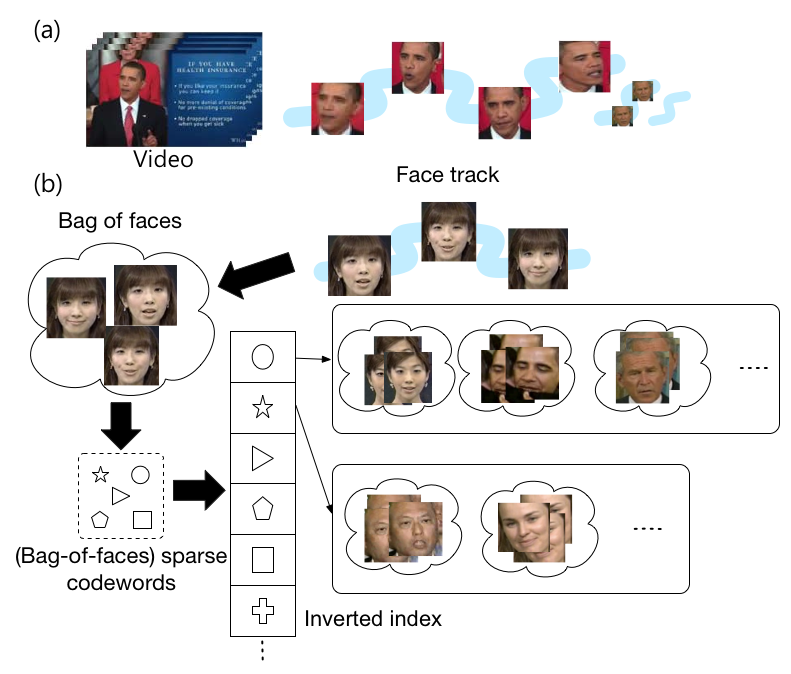
Huge video archives consisting of news programs, dramas, movies, and web videos (e.g., YouTube) are available in our daily life. In all these videos, human is usually one of the most important subjects. Using state-of-the-art techniques, we can efficiently detect and track faces in the videos. In order to organize large-scale face tracks, containing sequences of (detected) consecutive faces in the videos, we propose an efficient method to retrieve human face tracks using bag-of-faces sparse representation. Using the proposed method, a face track is encoded as a single bag-of-faces sparse representation and therefore allowing efficient indexing method to handle large-scale data. To further consider the possible variations in face tracks, we generalize our method to find multiple sparse representations, in an unsupervised manner, to represent a bag of faces and balance the trade-off between performance and retrieval time. Experimental results on two real-world (million-scale) datasets confirm that the proposed methods achieve significant performance gains compared to different state-of-the-art methods.