Learning Fine-Grained Visual Understanding for Video Question Answering via Decoupling Spatial-Temporal Modeling
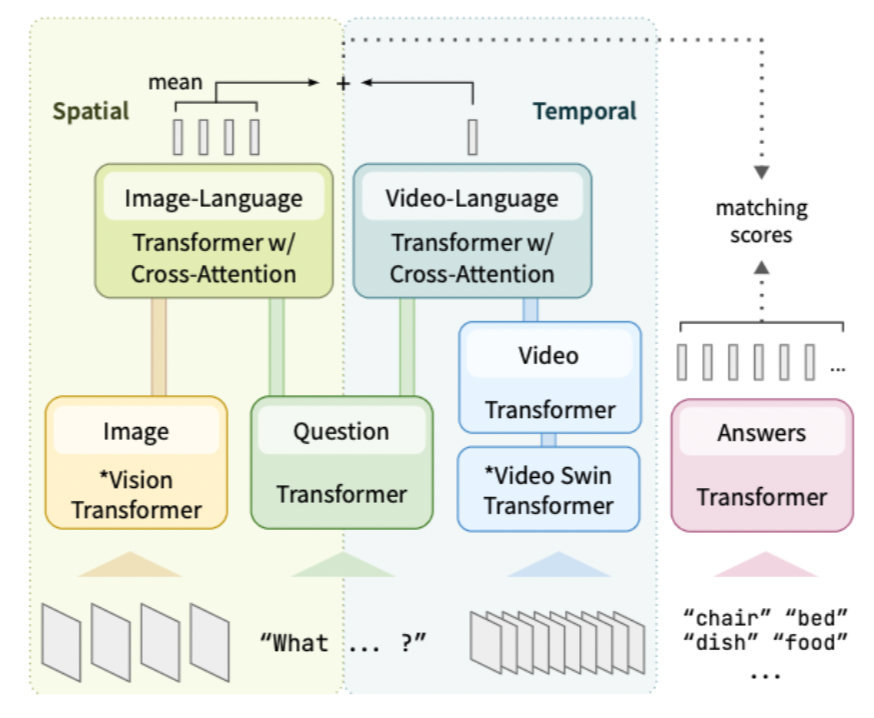
While recent large-scale video-language pre-training made great progress in video question answering, the design of spatial modeling is less fine-grained than that of image-language models; existing practices of temporal modeling also suffer from weak and noisy alignment between modalities. To learn fine-grained visual understanding, we decouple spatial-temporal modeling and propose a hybrid pipeline integrating an image- and a video-language encoder. The former encodes spatial semantics from larger but sparsely sampled frames independent of time, while the latter models temporal dynamics at lower spatial but higher temporal resolution. To help the video-language model learn temporal relations for video QA, we propose a novel pre-training objective, Temporal Referring Modeling, which requires the model to identify temporal positions of events in video sequences. Extensive and detailed experiments demonstrate that our model outperforms previous work that pre-trained on orders of magnitude larger datasets.