Learn from the Past – Sequentially One-to-One Video Deblurring Network
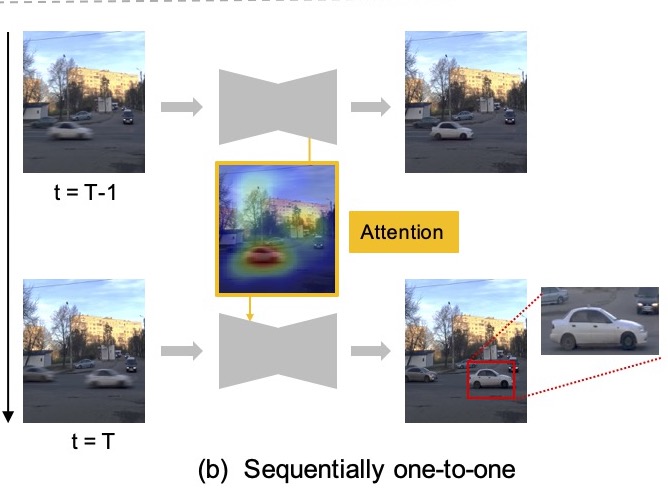
With the growing availability of hand-held cameras in recent years, more and more images and videos are taken at any time and any place. However, they usually suffer from undesirable blur due to camera shake or object motion in the scene. In recent years, a few modern video deblurring methods are proposed and achieve impressive performance. However, they are still not suitable for practical applications as high computational cost or using future information as input. To address the issues, we propose a sequentially one-to-one video deblurring network (SOON) which can deblur effectively without any future information. It transfers both spatial and temporal information to the next frame by utilizing the recurrent architecture. In addition, we design a novel Spatio-Temporal Attention module to nudge the network to focus on the meaningful and essential features in the past. Extensive experiments demonstrate that the proposed method outperforms the state-of-the-art deblurring methods, both quantitatively and qualitatively, on various challenging real-world deblurring datasets. Moreover, as our method deblurs in an online manner and is potentially real-time, it is more suitable for practical applications.
![]()
![]()