Exploiting Word and Visual Word Co-occurrence for Sketch-based Clipart Image Retrieval
Abstract
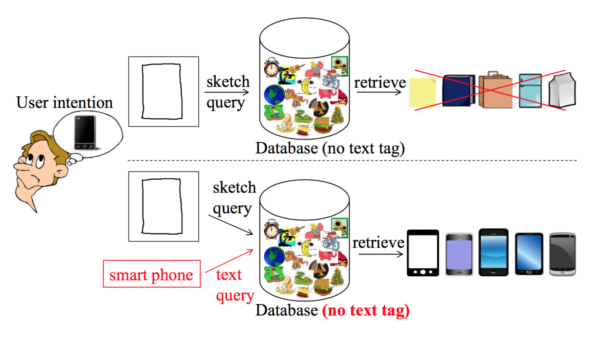
As the increasing popularity of touch-screen devices, retrieving images by hand-drawn sketch has become a trend. Human sketch can easily express some complex user intention such as the object shape. However, sketches are sometimes ambiguous due to different drawing styles and inter-class object shape ambiguity. Although adding text queries as semantic information can help removing the ambiguity of sketch, it requires a huge amount of efforts to annotate text tags to all database clipart images. We propose a method directly model the relationship between text and clipart images by the co-occurrence relationship between words and visual words, which improves traditional sketch-based image retrieval (SBIR), provides a baseline performance and obtains more relevant results in the condition that all images in database do not have any text tag. Experimental results show that our method really can help SBIR to get better retrieval result since it indeed learned semantic meaning from the “word-visual word” (W-VW) co-occurrence relationship.
Leave a Reply