DECCNet: Depth Enhanced Crowd Counting
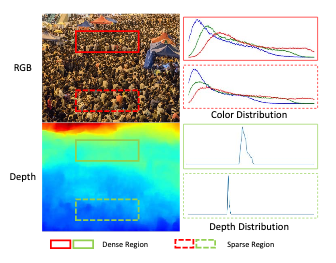
Crowd counting which aims to calculate the number of total instances on an image is a classic but crucial task that supports many applications. Most of the prior works are based on the RGB channels on the images and achieve satisfied performance. However, previous approaches suffer from counting highly congested region due to the in-complete and blurry shapes. In this paper, we present an effective crowd counting method, Depth Enhanced CrowdCounting Network (DECCNet), which leverages the estimated depth information with our novel BidirectionalCross-modal Attention (BCA) mechanism. Utilizing the depth information enables our model to explicitly learn to pay attention to those congested regions on the basis of the depth information. Our BCA mechanism interactively fuses two different input modalities by learning to focus on the in-formative parts according to each other. In our experiments, we demonstrate that DECCNet outperforms the state-of-the-art on the two largest crowd counting datasets avail-able, including UCF-QNRF, which has the highest crowd density. The visualized result shows that our method can accurately regress dense regions through leveraging depth information. Ablation studies also indicate that each component of our method is beneficial to final prediction.