Cross-Age Reference Coding for Age-Invariant Face Recognition and Retrieval
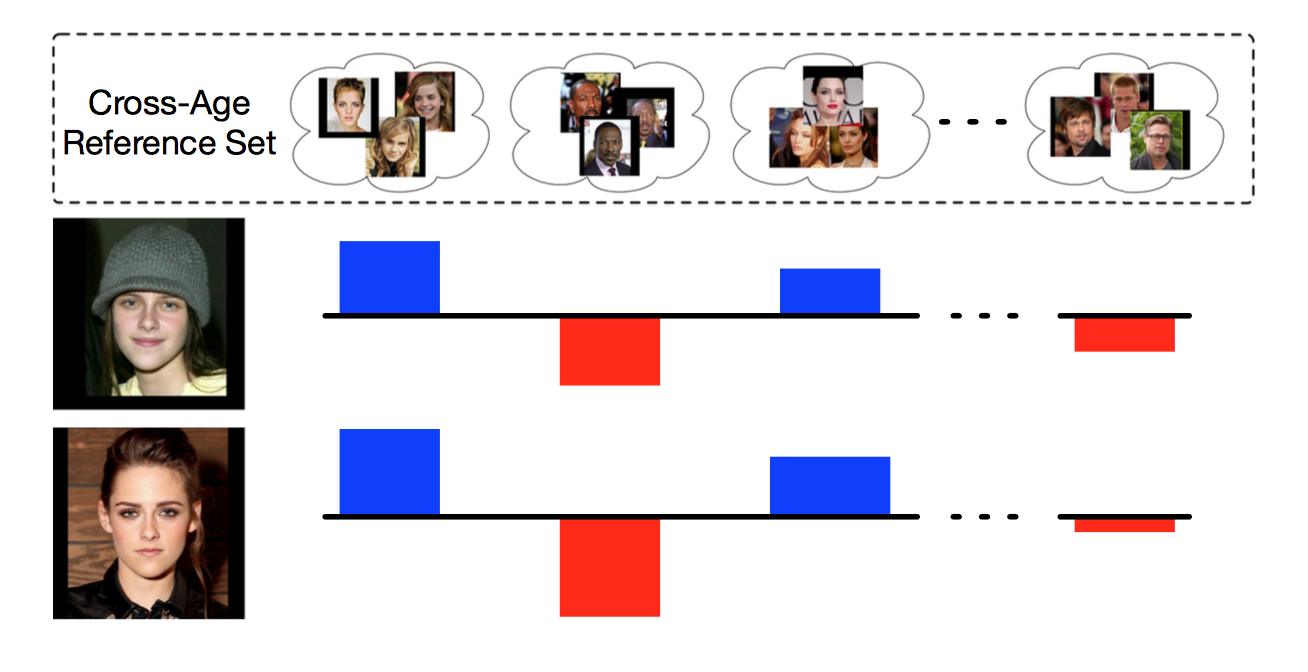
Recently, promising results have been shown on face recognition researches. However, face recognition and retrieval across age is still challenging. Unlike prior methods using complex models with strong parametric assumptions to model the aging process, we use a data-driven method to address this problem. We propose a novel coding framework called Cross-Age Reference Coding (CARC). By leveraging a large-scale image dataset freely available on the Internet as a reference set, CARC is able to encode the low-level feature of a face image with an age-invariant reference space. In the testing phase, the proposed method only requires a linear projection to encode the feature and therefore it is highly scalable. To thoroughly evaluate our work, we introduce a new large-scale dataset for face recognition and retrieval across age called Cross-Age Celebrity Dataset (CACD). The dataset contains more than 160,000 images of 2,000 celebrities with age ranging from 16 to 62. To the best of our knowledge, it is by far the largest publicly available cross-age face dataset. Experimental results show that the proposed method can achieve state-of-the-art performance on both our dataset as well as the other widely used dataset for face recognition across age, MORPH dataset.
Cross-Age Celebrity Dataset (CACD)
Cross-Age Celebrity Dataset (CACD) contains 163,446 images from 2,000 celebrities collected from the Internet. The images are collected from search engines using celebrity name and year (2004-2013) as keywords. We can therefore estimate the ages of the celebrities on the images by simply subtract the birth year from the year of which the photo was taken.