Automatic Training Image Acquisition and Effective Feature Selection from Community-Contributed Photos for Facial Attribute Detection
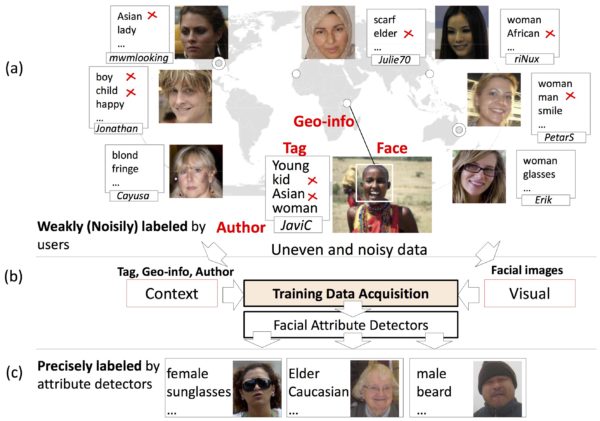
Facial attributes are shown effective for mining specific persons and profiling human activities in large-scale media such as surveillance videos or photo-sharing services. For comprehensive analysis, a rich number of facial attributes is required. Generally, each attribute detector is obtained by supervised learning via the use of large training data. It is promising to leverage the exponentially growing community contributed photos and the associated informative contexts to ease the burden of manual annotation; however, such huge noisy data from the Internet still pose great challenges. We propose to measure the quality of training images by discriminable visual features, which are verified with the relative discrimination between the unlabeled images and the pseudo-positives (pseudo-negatives) retrieved by textual relevance. The proposed feature selection requires no heuristic threshold, therefore, can be generalized to multiple feature modalities. We further exploit the rich context cues (e.g., tags, geo-locations, etc.) associated with the publicly available photos for mining more semantically consistent but visually diverse training images around the world. Experimenting in the benchmarks, we demonstrate that our work can successfully acquire effective training images for learning generic facial attributes, where the classification error is relatively reduced up to 23.35% compared with that of the text-based approach and shown comparable with that of costly manual annotations. (All of the face images presented in this paper except the training images in Fig. 8 attribute to various Flickr users under Creative Commons Licenses).