Automatic Facial Image Annotation and Retrieval by Integrating Voice Label and Visual Appearance
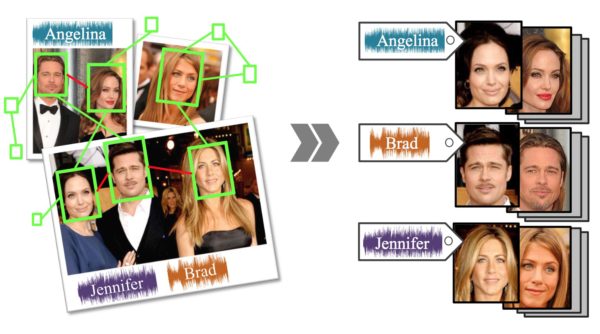
Annotation is important for managing and retrieving a large amount of photos, but it is generally labor-intensive and time-consuming. However, speaking while taking photos is straightforward and effortless, and using voice for annotation is faster than typing words. To best reduce the manual cost of annotating photos, we propose a novel framework which utilizes the scarce spoken annotations recorded while capturing as voice labels and automatically label every facial image in the photo collection. To accomplish this goal, we employ a probabilistic graphical model which integrates voice labels and visual appearances for inference. Combined with group prior estimation and gender attribute association, we can achieve an outstanding performance on the proposed synthesized group photo collections.