Approximating Weighted Hamming Distance by Probabilistic Selection for Multiple Hash Tables
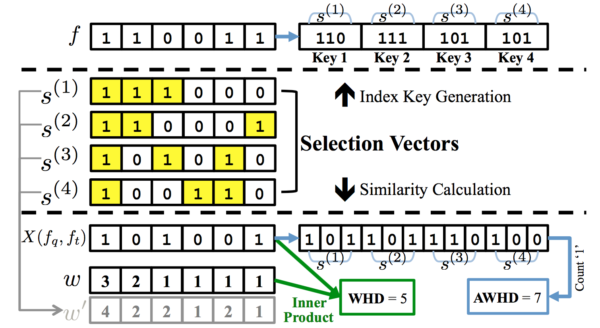
With the large growth of photos on the Internet, the need for large-scale, real-time image retrieval systems is emerging. Current state-of-the-art approaches in these systems leverage binary features (e.g., hashed codes) for indexing and matching. They usually (1) index data with multiple hash tables to maximize recall, and (2) utilize weighted hamming distance (WHD) to accurately measure the hamming distance between data points. However, these methods pose several challenges. The first is in determining suitable index keys for multiple hash tables. The second is that the advantage of bitwise operations for binary features is offset by the use of floating point operations in calculating WHD. To address these challenges, we propose a probabilistic selection model that considers the weights of hash bits in constructing hash tables, and that can be used to approximate WHD (AWHD). Moreover, it is a general method that can be applied to any binary features with predefined (learned) weights. Experiments show a time savings of up to 95% when calculating AWHD compared to WHD while still achieving high retrieval accuracy.