Egocentric activity recognition by leveraging multiple mid-level representations
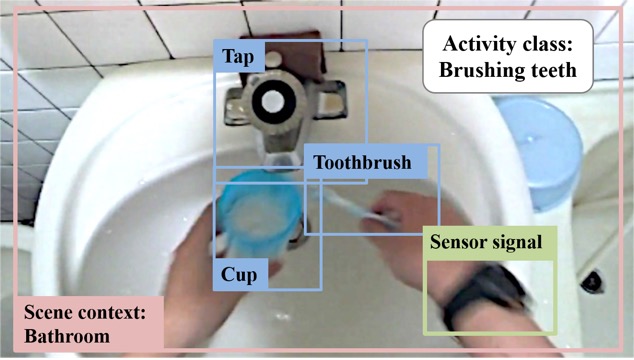
Existing approaches for egocentric activity recognition mainly rely on a single modality (e.g., detecting interacting objects) to infer the activity category. However, due to the inconsistency between camera angle and subject’s visual field, important objects may be partially occluded or missing in the video frames. Moreover, where the objects are and how we interact with the objects are usually ignored in prior works. To resolve these difficulties, we propose multiple mid-level representations (e.g., objects manipulated by a user, background context, and motion patterns of hands) to compensate the insufficiency of a single modality, and jointly consider what, where, and how a subject is interacting with. To evaluate the method, we introduce a new and challenging egocentric activity dataset (ADL+) that contains video and wrist-worn accelerometer data of people performing daily-life activities. Our approach significantly outperforms the state-of-the-art method on the public ADL dataset (i.e., 36.8% to 46.7%) and our ADL+ dataset (i.e., 32.1 % to 60.0%) in terms of classification accuracy. In addition, we also conduct a series of analyses to explore relative merits of each modality to egocentric activity recognition.