Mediated experts for deep convolutional networks
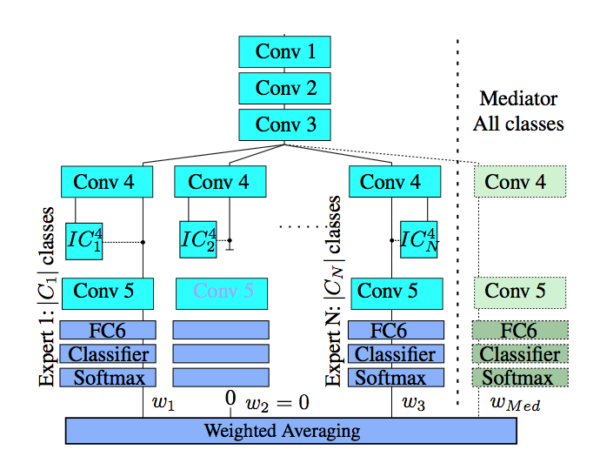
We present a new supervised architecture termed Mediated Mixture-of-Experts (MMoE) that allows us to improve classification accuracy of Deep Convolutional Networks (DCN). Our architecture achieves this with the help of expert networks: A network is trained on a disjoint subset of a given dataset and then run in parallel to other experts during deployment. A mediator is employed if experts contradict each other. This allows our framework to naturally support incremental learning, as adding new classes requires (re-)training of the new expert only. We also propose two measures to control computational complexity: An early-stopping mechanism halts experts that have low confidence in their prediction. The system allows to trade-off accuracy and complexity without further retraining. We also suggest to share low-level convo-lutional layers between experts in an effort to avoid computation of a near-duplicate feature set. We evaluate our system on a popular dataset and report improved accuracy compared to a single model of same configuration.